dubbo框架知识
一、Dubbo架构和实战
架构演变过程
单体架构
单体架构所有模块和功能都集中在一个项目中 ,部署时也是将项目所有功能整体部署到服务器中。
垂直架构
根据业务把项目垂直切割成多个项目。
分布式架构(SOA)
在垂直划分的基础上,将每个项目拆分出多个具备松耦合的服务,一个服务通常以独立的形式存在于操作系统进程中。
Dubbo三大核心能力:面向接口的远程方法调用,智能容错和负载均衡,以及服务自动注册和发现。
基于垂直结构进行分层:
应用层: 距离用户最近的一层也称之为接入层,使用tomcat作为web容器接收用户请求使用下游的dubbo提供的接口来返回数据并且该层禁止访问数据库。
业务服务层:根据具体的业务场景 演变而来的模块 比如 简历投递 职位搜索 职位推荐等。
基础业务层:招聘业务的核心 账号 简历 公司 职位。
基础服务层:这一层是与业务无关的模块是一些通用的服务,比如发短信,发邮件等等,这类服务请求量大但是逻辑简单。
存储层:不同的存储类型Mysql、Mongodb。
分级:二八定律,80%的流量在核心功能上,优先保证核心服务的稳定。
隔离:不同性质、不同重要业务要进行隔离,比如各种中间件。
优点:服务以接口为粒度,屏蔽远程调用底层细节,只关心结果,而且采用此业务分层架构清晰,模块职责单一,扩展性强,保证系统稳定且安全。
缺点:粒度控制复杂,模块越多可能引发超时,分布式事务问题,可能引发接口爆炸,版本升级兼容困难,调用链路长。
微服务架构
将单个应用程序作为一套小型服务开发的方法,每种应用程序都在其自己的进程中独立运行,并使用轻量级机制(通常是HTTP资源的API)进行通信。这些服务的集中化管理非常少,它们可以用不同的编程语言编写,并使用不同的数据存储技术。微服务是在SOA上做的升华 , 粒度更加细致,微服务架构强调的一个重点是业务需要彻底的组件化和服务化。
Dubbo基础知识
Apache Dubbo是一款高性能的Java RPC框架。

面向接口的远程方法调用:提供高性能的基于代理的远程调用能力,服务以接口为粒度,为开发者屏蔽远程调用底层细节。
智能容错和负载均衡:内置多种负载均衡策略,智能感知下游节点健康状况,显著减少调用延迟,提高系统吞吐量。
服务自动注册和发现:支持多种注册中心服务,服务实例上下线实时感知。
Dubbo服务治理:,企业为了确保项目顺利完成而实施的过程,包括最佳实践、架构原则、治理规程、规律以及其他决定性的因素。
Dubbo处理流程
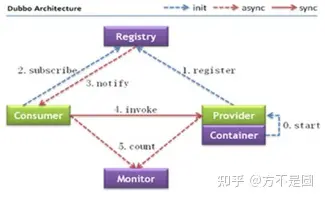
调用过程:
\1. 服务提供者在服务容器启动时向注册中心注册自己提供的服务。
\2. 服务消费者在启动时向注册中心订阅自己所需的服务。
\3. 注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心会基于长连接推送数据给消费者。
\4. 服务消费者从提供者地址列表中,基于软负载均衡算法选一台提供者进行调用,如果调用失败,重新选择。
\5. 服务提供者和服务消费者在内存中的调用次数和时间,定时每分钟发送给监控中心。
Dubbo配置方式
1.注解: 基于注解可以快速的将程序配置,无需多余的配置信息,包含提供者和消费者。弊端是根据配置信息无法快速定位。
\2. XML:和Spring做结合,相关的Service和Reference均使用Spring集成后的。通过这样的方式可以很方便的通过几个文件进行管理整个集群配置。可以快速定位也可以快速更改。
3.基于代码方式: 基于代码方式的对上述配置进行配置。
dubbo:application配置
代表当前应用的信息
\1. name: 当前应用程序的名称,在dubbo-admin中我们也可以看到,这个代表这个应用名称。我们在真正时是时也会根据这个参数来进行聚合应用请求。
\2. owner: 当前应用程序的负责人,可以通过这个负责人找到其相关的应用列表,用于快速定位到责任人。
\3. qosEnable : 是否启动QoS 默认true
\4. qosPort : 启动QoS绑定的端口 默认22222
\5. qosAcceptForeignIp: 是否允许远程访问 默认是false
注解方式

XML方式

dubbo:registry配置
代表该模块所使用的注册中心
\1. id : 当前服务中provider或者consumer中存在多个注册中心时,则使用需要增加该配置。在一 些公司,会通过业务线的不同选择不同的注册中心,所以一般都会配置该值。
\2. address : 当前注册中心的访问地址。
\3. protocol : 当前注册中心所使用的协议是什么。也可以直接在 address 中写入,比如使用 zookeeper,就可以写成 zookeeper://xx.xx.xx.xx:2181
\4. timeout : 当与注册中心不再同一个机房时,大多会把该参数延长。
dubbo:protocol配置
指定服务在进行数据传输所使用的协议
\1. id : 在大公司,可能因为各个部门技术栈不同,所以可能会选择使用不同的协议进行交互。这里 在多个协议使用时,需要指定。
\2. name : 指定协议名称。默认使用 dubbo 。
dubbo:service配置
指定当前需要对外暴露的服务信息
\1. interface : 指定当前需要进行对外暴露的接口是什么。
\2. ref : 具体实现对象的引用,一般我们在生产级别都是使用Spring去进行Bean托管的,所以这里面 一般也指的是Spring中的BeanId。
\3. version : 对外暴露的版本号。不同的版本号,消费者在消费的时候只会根据固定的版本号进行消 费。
dubbo:reference配置
消费者的配置
\1. id : 指定该Bean在注册到Spring中的id。
\2. interface: 服务接口名
\3. version : 指定当前服务版本,与服务提供者的版本一致。
\4. registry : 指定所具体使用的注册中心地址。这里面也就是使用上面在dubbo:registry中所声明的id。
dubbo:consumer设置
\1. mock: 用于在方法调用出现错误时,当做服务降级来统一对外返回结果,后面我们也会对这个方 法做更多的介绍。
\2. timeout: 用于指定当前方法或者接口中所有方法的超时时间。我们一般都会根据提供者的时长来 具体规定。比如我们在进行第三方服务依赖时可能会对接口的时长做放宽,防止第三方服务不稳定 导致服务受损。
\3. check: 用于在启动时,检查生产者是否有该服务。我们一般都会将这个值设置为false,不让其进 行检查。因为如果出现模块之间循环引用的话,那么则可能会出现相互依赖,都进行check的话, 那么这两个服务永远也启动不起来。
\4. retries: 用于指定当前服务在执行时出现错误或者超时时的重试机制,重试次数。
\1. 注意提供者是否有幂等,否则可能出现数据一致性问题
\2. 注意提供者是否有类似缓存机制,如出现大面积错误时,可能因为不停重试导致雪崩
\5. executes: 用于在提供者做配置,来确保最大的并行度,熔断处理。
\1. 可能导致集群功能无法充分利用或者堵塞
\2. 但是也可以启动部分对应用的保护功能
\3. 可以不做配置,结合后面的熔断限流使用
dubbo:method配置
XML中独有,指定具体方法级别在进行RPC操作时候的配置。
\1. name : 指定方法名称,用于对这个方法名称的RPC调用进行特殊配置。
\2. async: 是否异步 默认false
二、Dubbo高级应用
SPI
JDK内置的一种服务提供发现机制,使用SPI机制的优势是实现解耦, 使得第三方服务模块的装配控制逻辑与调用者的业务代码分离。

SPI约定
1) 当服务提供者提供了接口的一种具体实现后,在META-INF/services目录下创建一个以“接口全 限定名”为命名的文件,内容为实现类的全限定名。
2) 接口实现类所在的jar包放在主程序的classpath中。
3) 主程序通过java.util.ServiceLoader动态装载实现模块,它通过扫描META-INF/services目录下 的配置文件找到实现类的全限定名,把类加载到JVM。
4) SPI的实现类必须携带一个无参构造方法。
Dubbo中的SPI
dubbo中大量的使用了SPI来作为扩展点,通过实现同一接口的前提下,可以进行定制自己的实现类。 比如比较常见的协议,负载均衡,都可以通过SPI的方式进行定制化,自己扩展。
优点:
\1. JDK 标准的 SPI 会一次性实例化扩展点所有实现,如果有扩展实现初始化很耗时,但如果没用上也加载,会很浪费资源。
\2. 如果有扩展点加载失败,则所有扩展点无法使用。
\3. 提供了对扩展点包装的功能(Adaptive),并且还支持通过set的方式对其他的扩展点进行注入。
Adaptive功能
Dubbo中的Adaptive功能,主要解决的问题是如何动态的选择具体的扩展点。通过 getAdaptiveExtension 统一对指定接口对应的所有扩展点进行封装,通过URL的方式对扩展点来进行 动态选择。

Dubbo过滤器
Dubbo的Filter机制,是专门为服务提供方和服务消费方调用过程进行拦截设计的,每次远程方法执行,该拦截都会被执行。这样就为开发者提供了非常方便的扩展性,比如为dubbo接口实现ip白名单功 能、监控功能 、日志记录等。

负载均衡策略
负载均衡(Load Balance), 其实就是将请求分摊到多个操作单元上进行执行,从而共同完成工作任务。负载均衡策略主要用于客户端存在多个提供者时进行选择某个提供者。在集群负载均衡时,Dubbo 提供了多种均衡策略(包括随机、轮询、最少活跃调用数、一致性 Hash),dubbo默认为随机调用。

自定义负载均衡器开发
1) 自定义负载均衡器
2) 配置负载均衡器 META-INF/dubbo
3) 在服务提供者工程实现类中编写用于测试负载均衡效果的方法,启动不同端口时,方法返回的信息不同。
4) 启动多个服务 要求他们使用同一个接口注册到同一个注册中心 但是他们的dubbo通信端口不同
5) 在服务消费方指定自定义负载均衡器
异步调用
Dubbo不只提供了堵塞式的的同步调用,同时提供了异步调用的方式。这种方式主要应用于提供者接口
响应耗时明显,消费者端可以利用调用接口的时间去做一些其他的接口调用,利用 Future 模式来异步等待和获取结果即可。
线程池
Dubbo两种线程池
1) fix: 表示创建固定大小的线程池。Dubbo默认的使用方式,默认创建的执行线程数为200,并且是没有任何等待队列的。大量操作同步执行可能阻塞。
2) cache: 创建非固定大小的线程池,当线程不足时,会自动创建新的线程。高TPS(每秒请求数)请求下,对系统CPU和负载压力大。
自定义线程池
真实的使用过程中可能会因为使用fix模式的线程池,导致具体某些业务场景因为线程池中的线程数量不足而产生错误,而很多业务研发是对这些无感知的,只有当出现错误的时候才会去查看告警或者通过客户反馈出现严重的问题才去查看,结果发现是线程池满了。所以可以在创建线程池的时,通过某些手段对这个线程池进行监控,这样就可以进行及时的扩缩容机器或者告警。

路由规则
路由是决定一次请求中需要发往目标机器的重要判断,通过对其控制可以决定请求的目标机器。我们可以通过创建这样的规则来决定一个请求会交给哪些服务器去处理。
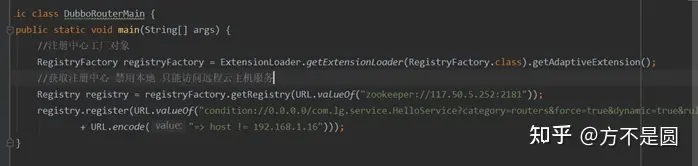
规则详解:
route:// 表示路由规则的类型,支持条件路由规则和脚本路由规则,可扩展,必填。
0.0.0.0 表示对所有 IP 地址生效,如果只想对某个 IP 的生效,请填入具体 IP,必填。
com.lagou.service.HelloService 表示只对指定服务生效,必填。
category=routers 表示该数据为动态配置类型,必填。
dynamic : 是否为持久数据,当指定服务重启时是否继续生效。必填。
runtime : 是否在设置规则时自动缓存规则,如果设置为true则会影响部分性能。
… => … 在这里 => 前面的就是表示消费者方的匹配规则,可以不填(代表全部)。 => 后方则必 须填写,表示当请求过来时,如果选择提供者的配置。
服务降级
服务降级,当服务器压力剧增的情况下,根据当前业务情况及流量对一些服务有策略的降低服务级别, 以释放服务器资源,保证核心任务的正常运行。使用服务降级,这是防止分布式服务发生雪崩效应,当一个请求发生超时,一直等待着服务响应,那么在高并发情况下,很多请求都是因为这样一直等着响应,直到服务资源耗尽产生宕机,而宕机之后会导致分布式其他服务调用该宕机的服务也会出现资源耗尽宕机, 这样下去将导致整个分布式服务都瘫痪,这就是雪崩。
降级方式:
1) 在 dubbo 管理控制台配置服务降级,屏蔽和容错。
2) 指定返回简单值或者null
3) 使用java代码 动态写入配置中心
4) 整合hystrix
三、Dubbo源码剖析
Dubbo调用过程

调用四部分
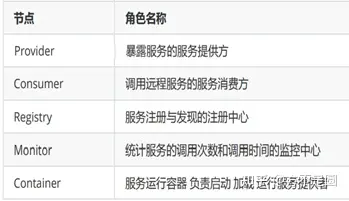
1)Provider: 暴露服务的服务提供方
Protocol 负责提供者和消费者之间协议交互数据
Service 真实的业务服务信息 可以理解成接口 和 实现
Container Dubbo的运行环境
2)Consumer: 调用远程服务的服务消费方
Protocol 负责提供者和消费者之间协议交互数据
Cluster 感知提供者端的列表信息
Proxy 可以理解成 提供者的服务调用代理类 由它接管 Consumer中的接口调用逻辑
3)Registry: 注册中心,用于作为服务发现和路由配置等工作,提供者和消费者都会在这里进行注册
4)Monitor: 用于提供者和消费者中的数据统计,比如调用频次,成功失败次数等信息。
启动和执行流程
1)提供者端启动 容器负责把Service信息加载 并通过Protocol 注册到注册中心
2)消费者端启动 通过监听提供者列表来感知提供者信息 并在提供者发生改变时 通过注册中心及时通知消费端
3)消费方发起 请求 通过Proxy模块
4)利用Cluster模块 来选择真实的要发送给的提供者信息
5)交由Consumer中的Protocol 把信息发送给提供者
6)提供者同样需要通过 Protocol 模块来处理消费者的信息
7)最后由真正的服务提供者 Service 来进行处理
整体调用链路
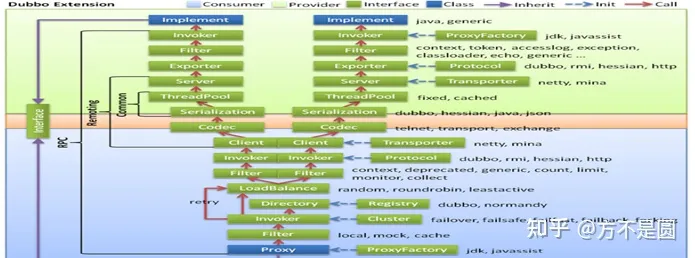
1)消费者通过Interface进行方法调用 统一交由消费者端的 Proxy 通过ProxyFactory 来进行代理 对象的创建 使用到了 jdk javassist技术
2)交给Filter 这个模块 做一个统一的过滤请求 在SPI案例中涉及过
3)接下来会进入最主要的Invoker调用逻辑
通过Directory 去配置中新读取信息 最终通过list方法获取所有的Invoker
通过Cluster模块 根据选择的具体路由规则 来选取Invoker列表
通过LoadBalance模块 根据负载均衡策略 选择一个具体的Invoker 来处理我们的请求
如果执行中出现错误 并且Consumer阶段配置了重试机制 则会重新尝试执行
4) 继续经过Filter进行执行功能的前后封装 Invoker 选择具体的执行协议 、
5) 客户端 进行编码和序列化然后发送数据
6) 到达Consumer中的Server在这里进行反编码和反序列化的接收数据
7) 使用Exporter选择执行器
8) 交给Filter 进行一个提供者端的过滤到达 Invoker 执行器
9) 通过Invoker 调用接口的具体实现然后返回
URL规则和服务本地缓存
Dubbo中的URL与java中的URL差异
1) 这里提供了针对于参数的 parameter 的增加和减少(支持动态更改)
2) 提供缓存功能,对一些基础的数据做缓存
服务本地缓存
频繁往从ZK获取信息,肯定会存在单点故障问题,所以dubbo提供了将提供者信息缓存在本地的方法,主要实现就是创建一个properties文件,通过构造方法从远程一拿到配置信息就存储到本地进行缓存。
Dubbo服务消费过程
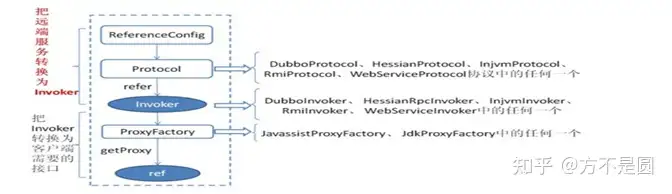
1)通过ReferenceConfig 类的Protocol 调用 refer 方法让远程对象生成 Invoker 实例。
2)接着通过ProxyFactory的getProxy方法生成ref代理对象对远程服务进行处理。
Adaptive功能实现原理
Adaptive的主要功能是对所有的扩展点进行封装为一个类,通过URL传入参数的时动态选择需要使用的扩展点。其底层的实现原理就是动态代理。
集群容错分析
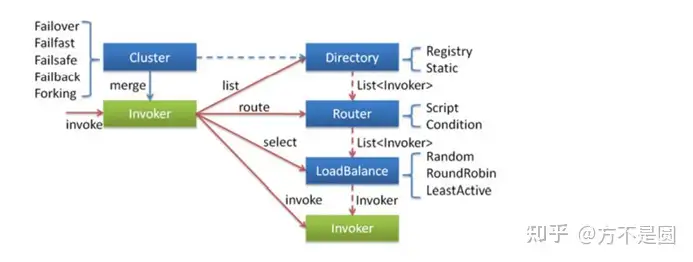
Dubbo 主要提供了这样几种容错方式
Failover Cluster - 失败自动切换 失败时会重试其它服务器
Failfast Cluster - 快速失败请求失败后快速返回异常结果不重试
Failsafe Cluster - 失败安全出现异常 直接忽略 会对请求做负载均衡
Failback Cluster - 失败自动恢复请求失败后 会自动记录请求到失败队列中
Forking Cluster - 并行调用多个服务提供者 其中有一个返回则立即返回结果
信息缓存接口Directory
Directory是Dubbo中的一个接口,主要用于缓存当前可以被调用的提供者列表信息。我们在消费者进 行调用时都会通过这个接口来获取所有的提供者列表,再进行后续处理。
负载均衡实现原理
通过LoadBalance 接口进行定义,默认使用的是随机算法,这随机算法的负载,其内部的实现其实就是一个权重概念,通过不同权重来选取不同机器。权重相同直接随机,权重不同通过总工权重来随机分配。
网络通信原理剖析
dubbo协议采用固定长度的消息头和不定长度的消息体来进行数据传输。请求、响应的 header 一致。
 微信打赏
微信打赏