mysql架构原理相关知识
体系架构
MySQL Server架构自顶向下大致可以分网络连接层、服务层、存储引擎层和系统文件层。
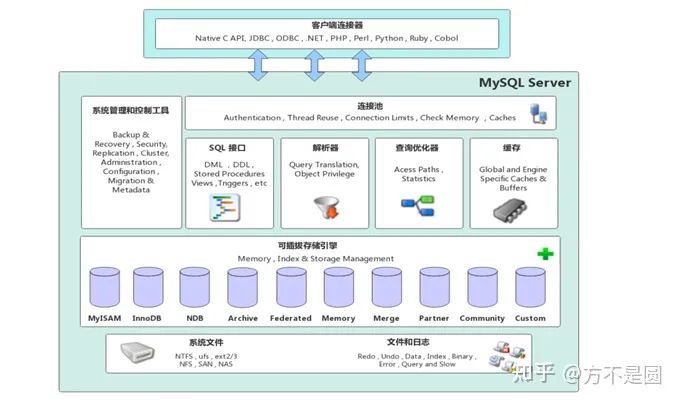
网络连接层
客户端连接器:提供与MySQL服务器建立的支持。
服务层
主要包含系统管理和控制工具、连接池、SQL接口、解析器、查询优化器和缓存六个部分。
1) 连接池:存储和管理客户端与数据库的连接。
2) 系统管理和控制工具:集群、备份、安全管理。
3) SQL接口:接受客户端发送的各种SQL命令并返回查询结果。
4) 解析器:解析SQL,生成一颗解析树,验证SQL是否合法。
5) 查询优化器:将解析树转化成执行计划,与存储引擎进行交互。
6) 缓存:各种缓存,比如表、记录、权限等等,缓存有命中查询结果直接返回。
存储引擎层
负责MySQL中数据的存储与提取,与底层系统文件进行交互,可插拔,常见的两类:MyISAM和InnoDB。
系统文件层
负责将数据库的数据和日志存储在文件系统之上,并完成与存储引擎的交互,比如日志、配置文件等等。
错误日志查询:show variables like ‘%log_error%’
通用查询日志:show variables like ‘%general%’;
二进制日志(恢复和主从复制):show binary logs;
慢查询日志(记录超时,默认10秒):show variables like ‘%slow_query%’;
配置文件: 存放MySQL所有的配置信息文件。
运行机制
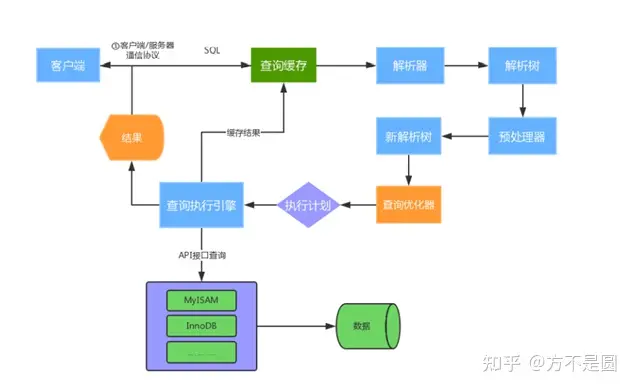
1) 建立连接,通过客户端/服务器通信协议与MySQL建立连接。通信方式是半双工,也就是不能同时即发送数据也接收数据,除此之外还有全双工和单工,通过show processlist;可以查看用户正在运行的线程信息。
2) 查询缓存,开启了查询缓存且在查询缓存过程中查询到完全相同的SQL语句,则将查询结果直接返回给客户端,没有的话则进入下一环节。不过查询的结果大于query_cache_limit设置或者存在不确定参数,比如now()不会走缓存。show variables like ‘%query_cache%’;可查看缓存信息。
3) 解析器,将客户端发送的SQL进行语法解析,生成”解析树”,并检验SQL是否合法。
4) 查询优化器,根据“解析树”生成最优的执行计划,其实就是SQL优化,比如in排序,max函数等等。
5) 查询执行引擎,根据 SQL 语句中表的存储引擎类型,以及对应的API接口与底层存储引擎缓存或者物理文件的交互,得到查询结果并返回给客户端,如果开启了查询缓存,会把结果存入缓存中,并且返回方式是增量返回,不是一次性全部返回。
存储引擎
根据MySQL提供的文件访问层抽象接口定制的一种文件访问机制,负责MySQL中的数据的存储和提取。5.5版本之前默认采用MyISAM存储引擎,5.5开始采用InnoDB存储引擎。
InnoDB和MyISAM对比
1)事务和外键
InnoDB支持事务和外键,具有安全性和完整性,适合大量insert或update操作
MyISAM不支持事务和外键,它提供高速存储和检索,适合大量的select查询操作
2)锁机制
InnoDB支持行级锁,锁定指定记录。基于索引来加锁实现。
MyISAM支持表级锁,锁定整张表。
3)索引结构
InnoDB使用聚集索引(聚簇索引),索引和记录在一起存储,既缓存索引,也缓存记录。
MyISAM使用非聚集索引(非聚簇索引),索引和记录分开。
4)并发处理能力
MyISAM使用表锁,会导致写操作并发率低,读之间并不阻塞,读写阻塞。
InnoDB读写阻塞可以与隔离级别有关,可以采用多版本并发控制(MVCC)来支持高并发
5)存储文件
InnoDB表对应两个文件,一个.frm表结构文件,一个.ibd数据文件。InnoDB表最大支持64TB;
MyISAM表对应三个文件,一个.frm表结构文件,一个MYD表数据文件,一个.MYI索引文件。默认限制是256TB。
6)MyISAM适用场景
不需要事务支持(不支持)
并发相对较低(锁定机制问题)
数据修改相对较少,以读为主
数据一致性要求不高
7)InnoDB适用场景
需要事务支持(具有较好的事务特性)
行级锁定对高并发有很好的适应能力
数据更新较为频繁的场景
数据一致性要求较高
硬件设备内存较大,可以利用InnoDB较好的缓存能力来提高内存利用率,减少磁盘IO
InnoDB存储结构
MySQL 5.5版本开始默认使用InnoDB作为引擎,它擅长处理事务,具有自动崩溃恢复的特性。
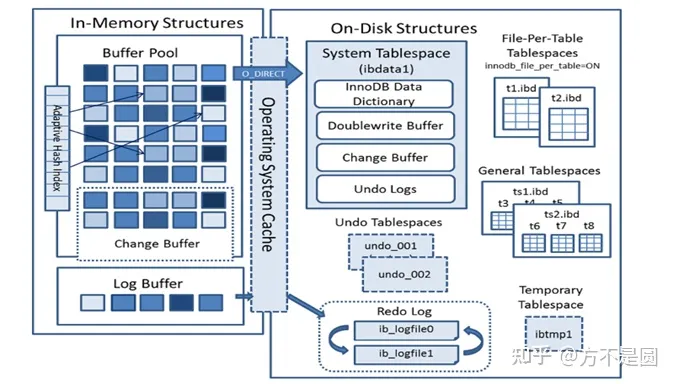
内存结构主要包括Buffer Pool、Change Buffer、Adaptive Hash Index和Log Buffer四大组件。
Buffer Pool
缓冲池,简称BP。BP以Page页为单位,默认大小16K,BP的底层采用链表数据结构管理Page。通过改进型LRU算法维护,即中间插入,命中往头部移动,未命中往尾部移动,实行末尾淘汰。
建议:将innodb_buffer_pool_size设置为总内存大小的60%-80%,innodb_buffer_pool_instances可以设置为多个,这样可以避免缓存争夺。
Change Buffer
写缓冲区,简称CB。在进行DML操作时,如果BP没有其相应的Page数据,并不会立刻将磁盘页加载到缓冲池,而是在CB记录缓冲变更,等未来数据被读取时,再将数据合并恢复到BP中,默认占BP的25%。
Adaptive Hash Index
自适应哈希索引,用于优化对BP数据的查询。InnoDB存储引擎会自动根据访问的频率和模式来为某些页建立哈希索引。
Log Buffer
日志缓冲区,保存要写入磁盘上log文件(Redo/Undo)的数据,日志缓冲区的内容定期刷新到磁盘log文件中。
缓冲区满自动刷新到磁盘。
InnoDB磁盘结构
InnoDB磁盘主要包含Tablespaces,InnoDB Data Dictionary,Doublewrite Buffer、Redo Log 和Undo Logs。
表空间(Tablespaces)
存储表结构和数据。并且分为系统表空间、独立表空间、 通用表空间、临时表空间、Undo表空间等多种类型。
1) 系统表空间:默认包含任何用户在系统表空间创建的表数据和索引数据,是InnoDB Data Dictionary,Doublewrite Buffer,Change Buffer,Undo Logs的存储区域。
2) 独立表空间:默认开启,独立表空间是一个单表表空间,该表创建于自己的数据文件中,而非创建于系统表空间中。
3) 通用表空间:通用表空间为通过create tablespace语法创建的共享表空间。
4) 撤销表空间:撤销表空间由一个或多个包含Undo日志文件组成。
5) 临时表空间:分为session temporary tablespaces 和global temporary tablespace两种。session temporary tablespaces 存储的是用户创建的临时表和磁盘内部的临时表。global temporary tablespace储存用户临时表的回滚段。
数据字典(InnoDB Data Dictionary)
InnoDB数据字典由内部系统表组成,这些表包含用于查找表、索引和表字段等对象的元数据。
双写缓冲区(Doublewrite Buffer)
位于系统表空间,是一个存储区域。在BufferPage的page页刷新到磁盘真正的位置前,会先将数据存在Doublewrite 缓冲区,当出现进程崩溃,从这里获取数据并恢复。
重做日志(Redo Log)
重做日志是一种基于磁盘的数据结构,用于在崩溃恢复期间更正不完整事务写入的数据。MySQL以循环方式写入重做日志文件,记录InnoDB中所有对Buffer Pool修改的日志,当出现崩溃从重做日志中把数据更新到数据文件。
撤销日志(Undo Logs)
撤消日志是在事务开始之前保存的被修改数据的备份,用于例外情况时回滚事务。撤消日志属于逻辑日志,根据每行记录进行记录。
版本差异
5.7版本:Undo日志表空间从共享表空间分离,安装时可自由指定,增加临时表空间,并且可动态修改Buffer Pool
8.0版本:数据字典和Undo、Doublewrite Buffer都从共享表空间分离,临时表空间可以配置多个物理文件。
InnoDB线程模型
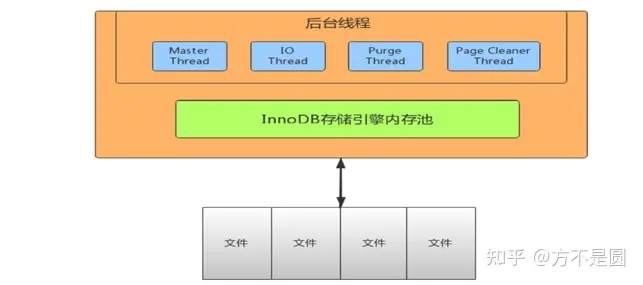
IO Thread
使用了大量的AIO(Async IO)来做读写处理,10个IO Thread,分别是write(4),read(4),insert buffer和log thread。
Purge Thread
事务提交之后,回收已经分配的undo 页。
Page Cleaner Thread
将脏数据刷新到磁盘,脏数据刷盘后相应的redo log也就可以覆盖,即可以同步数据,又能达到redo log循环使用的目的。
Master Thread
Master thread是InnoDB的主线程,负责调度其他各线程,优先级最高。作用是将缓冲池中的数据异步刷新到磁盘 ,保证数据的一致性,比如脏页的刷新、undo页回收、redo日志刷新、合并写缓冲等,分1秒和10秒执行。
InnoDB数据文件
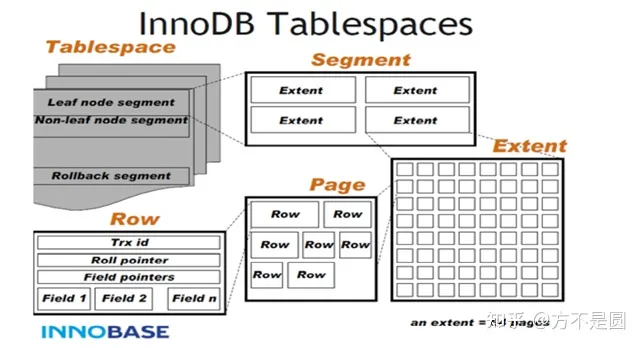
InnoDB数据文件存储结构:分为一个ibd数据文件->Segment(段)->Extent(区)->Page(页)->Row(行)
Tablesapce:表空间,用于存储多个ibd数据文件,用于存储表的记录和索引。一个文件包含多个段。
Segment:段,用于管理多个Extent,分为数据段、索引段、回滚段。
Extent:区,一个区固定包含64个连续的页,大小为1M。
Page:页,用于存储多个Row行记录,大小为16K。包含很多种页类型,比如数据页,undo页,系统页等等。
Row:行,包含了记录的字段值,事务ID、滚动指针、字段指针等信息。
InnoDB只支持两种文件格式:Antelope 和 Barracuda。
InnoDB存储引擎支持四种行格式:REDUNDANT、COMPACT、DYNAMIC和COMPRESSED。
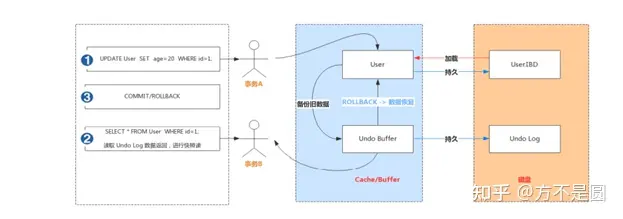
Undo Log
数据库事务开始之前,会将要修改的记录存放到 Undo 日志里,当事务回滚时或者数据库崩溃时,可以利用 Undo 日志,撤销未提交事务对数据库产生的影响。事务提交之后也不会马上删除,而是进入删除队列待删除。Undo Log属于逻辑日志,记录一个变化过程,采用段的方式管理和记录。例如执行一个delete,undolog会记录一个insert;执行一个update,undolog会记录一个相反的update。
1) 实现事务的原子性
事务处理过程中,如果出现了错误或者用户执行了 ROLLBACK 语句,MySQL可以利用 Undo Log中的备份将数据恢复到事务开始之前的状态。
2) 实现多版本并发控制(MVCC)
事务未提交之前,Undo Log保存了未提交之前的版本数据,Undo Log中的数据可作为数据旧版本快照供其他并发事务进行快照读。
Redo Log
指事务中修改的任何数据,将最新的数据备份存储的位置(Redo Log),被称为重做日志。事务操作的执行,就会生成Redo Log,在事务提交时会将产生Redo Log写入Log Buffer。等事务操作的脏页写入到磁盘之后,Redo Log占用的空间会被覆盖写入。
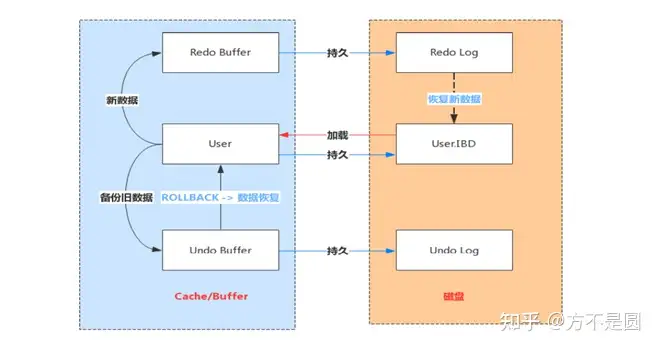
Redo Log 文件内容是以顺序循环的方式写入文件,写满时则回溯到第一个文件,进行覆盖写。
Binlog日志
MySQL Server的日志,即Binary log(二进制日志),简称Binlog。Binlog是记录所有数据库表结构变更以及表数据修改的二进制日志,不会记录SELECT和SHOW这类操作。Binlog日志是以事件形式记录,还包含语句所执行的消耗时间。用于主从复制和数据恢复。
Binlog文件名默认为“主机名_binlog-序列号”格式,文件记录模式有STATEMENT、ROW和MIXED三种。
Binlog文件结构
MySQL的binlog文件中记录的是对数据库的各种修改操作,用来表示修改操作的数据结构是Log event。

Binlog写入机制
1) 根据记录模式和操作触发event事件生成log event(事件触发执行机制)
2) 将事务执行过程中产生log event写入缓冲区,每个事务线程都有一个缓冲区,存放两个缓冲区,即支持事务和不支持事务的缓冲区。
3) 事务在提交阶段会将产生的log event写入到外部binlog文件中,以串行写入,保证连续性。
Binlog文件操作
状态查看:show variables like ‘log_bin’;
开启Binlog功能:set global log_bin=mysqllogbin;
使用 binlog 恢复数据:
mysqlbinlog–start-datetime=”2020-04-25 18:00:00” –stopdatetime=”2020-04-26 00:00:00” mysqlbinlog.000002 | mysql -uroot -p1234 //按指定时间恢复
mysqlbinlog –start-position=154 –stop-position=957 mysqlbinlog.000002 | mysql -uroot -p1234//按事件位置号恢复
删除Binlog文件:purge binary logs to ‘mysqlbinlog.000001’; //删除指定文件
可以通过设置expire_logs_days参数来启动自动清理功能。默认值为0表示没启用。设置为1表示超 出1天binlog文件会自动删除掉。
 微信打赏
微信打赏