mysql索引原理相关知识
索引类型
索引可以提升查询速度,会影响where查询,以及order by排序,分为B Tree索引、Hash索引、FULLTEXT全文索引、R Tree索引、普通索引、唯一索引、主键索引、复合索引、主键索引、辅助索引、聚集索引(聚簇索引)、非聚集索引(非聚簇索引)
1) 普通索引:这是最基本的索引类型,基于普通字段建立的索引,没有任何限制。
ALTER TABLE tablename ADD INDEX [索引的名字] (字段名);
2) 唯一索引:索引字段的值必须唯一,但允许有空值 。
ALTER TABLE tablename ADD UNIQUE INDEX [索引的名字] (字段名);
3) 主键索引:它是一种特殊的唯一索引,不允许有空值。
ALTER TABLE tablename ADD PRIMARY KEY (字段名);
4) 复合索引:用户可以在多个列上建立索 引,这种索引叫做组复合索引,分窄索引和宽索引,使用复合索引,要根据where条件建索引。
ALTER TABLE tablename ADD INDEX [索引的名字] (字段名1,字段名2…);
5) 全文索引:对于大量的文本数据检索,使用模糊查询效率很低。使用全文索引,查询速度会比like快很多倍。全文索引字段值可以进行切词模糊查询。
创建方式:ALTER TABLE tablename ADD FULLTEXT [索引的名字] (字段名); CREATE TABLE tablename ( […], FULLTEXT KEY [索引的名字] (字段名
索引原理
索引是存储引擎用于快速查找记录的一种数据结构,物理数据页存储。需要额外开辟空间和数据维护工作,索引可以加快检索速度,但是同时也会降低增删改操作速度。
二分查找法
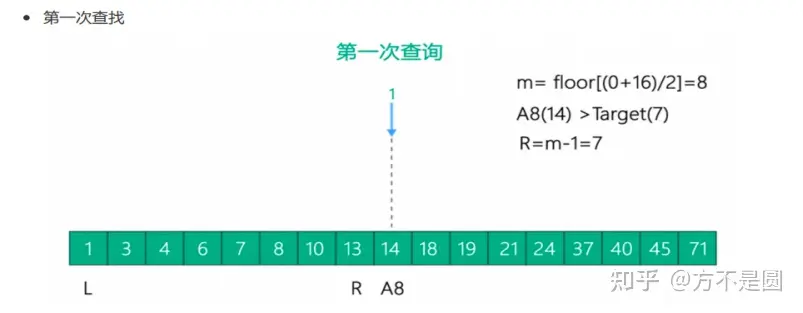
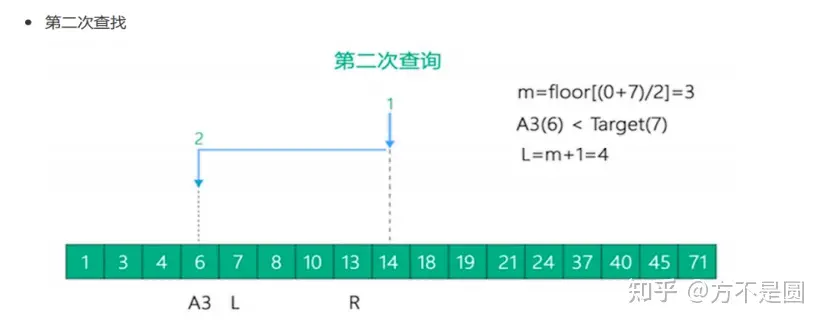
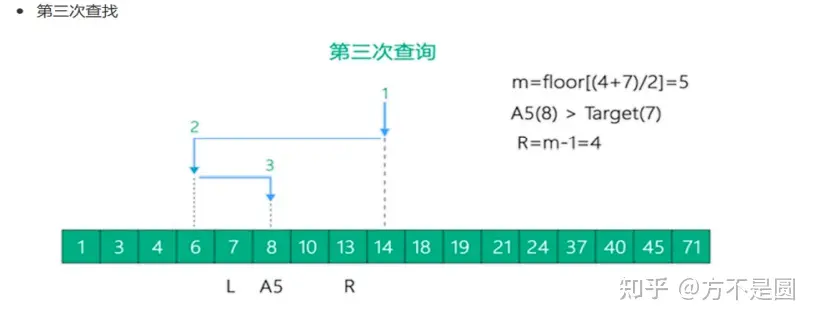
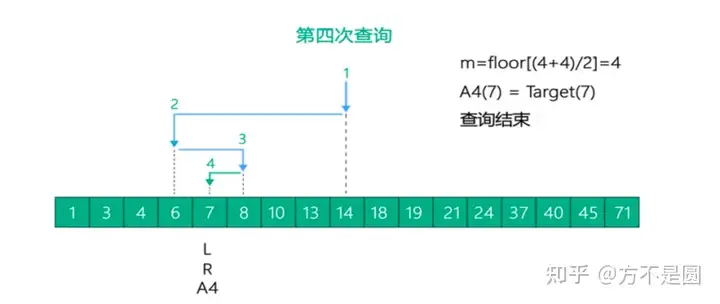
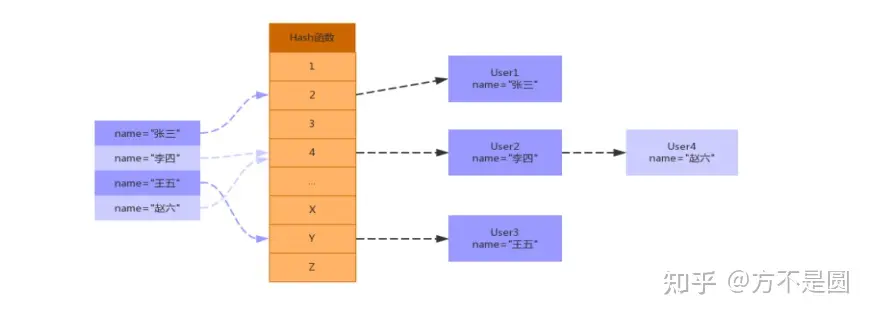
Hash结构
Hash底层实现是由Hash表来实现的,是根据键值存储数据的结构。
B+Tree结构
MySQL数据库索引采用的是B+Tree结构,在B-Tree结构上做了优化改造。
B-Tree结构
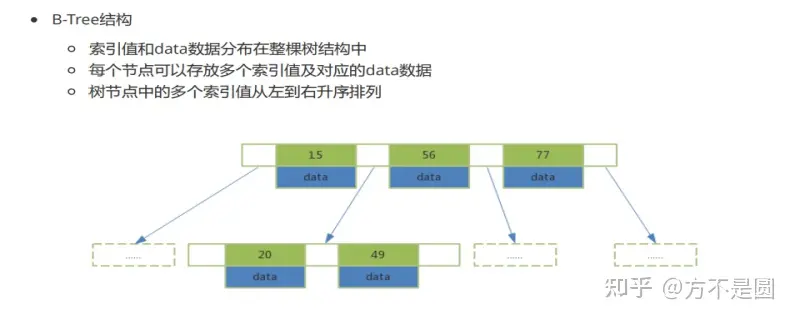
原理:从根节点开始,对节点内的索引值序列采用二分法查找,如果命中就结束查找。没有命中会进入子节点重复查找过程,直到所对应的的节点指针为空,或已经是叶子节点了才结束。
B+Tree结构
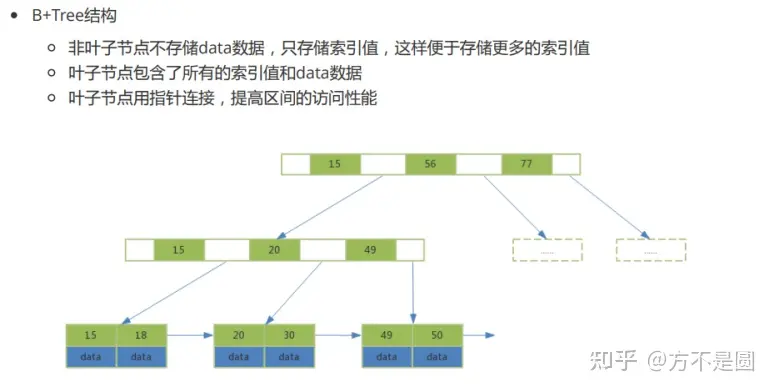
B+树进行范围查找时,只需要查找定位两个节点的索引值,然后利用叶子节点的指针进行遍历。
聚簇索引和辅助索引
B+Tree的叶子节点存放主键索引值和行记录就属于聚簇索引;如果索引值和行记录分开存放就属于非聚簇索引。
B+Tree的叶子节点存放的是主键字段值就属于主键索引;如果存放的是非主键值 就属于辅助索引。
聚簇索引:如果表定义了主键,则主键索引就是聚簇索引,否则第一个非空unique列作为聚簇索引,不然自建隐藏索引。
辅助索引:一个表InnoDB只能创建一个聚簇索引,但可以创建多个辅助索引。
非聚簇索引: MyISAM数据表的索引文件和数据文件是分开的,被称为非聚簇索引结构。
Explain分析
EXPLAIN 命令用于对 SELECT 语句进行分析,并输出 SELECT 执行的详细信息。
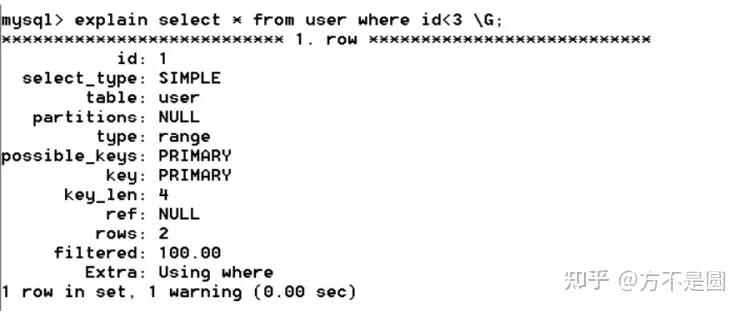
select_type查询的类型
SIMPLE : 表示查询语句不包含子查询或union
PRIMARY:表示此查询是最外层的查询
UNION:表示此查询是UNION的第二个或后续的查询
DEPENDENT UNION:UNION中的第二个或后续的查询语句,使用了外面查询结果
UNION RESULT:UNION的结果
SUBQUERY:SELECT子查询语句
DEPENDENT SUBQUERY:SELECT子查询语句依赖外层查询的结果。
type
ALL:表示全表扫描,性能最差。
index:表示基于索引的全表扫描,先扫描索引再扫描全表数据。
range:表示使用索引范围查询。使用>、>=、<、<=、in等等。
ref:表示使用非唯一索引进行单值查询。
eq_ref:一般情况下出现在多表join查询,表示前面表的每一个记录,都只能匹配后面表的一 行结果。
const:表示使用主键或唯一索引做等值查询,常量查询。
NULL:表示不用访问表,速度最快。
possible_keys
表示查询时能够使用到的索引。注意并不一定会真正使用,显示的是索引名称。
key
表示查询时真正使用到的索引,显示的是索引名称。
rows
MySQL查询优化器会根据统计信息,估算SQL要查询到结果需要扫描多少行记录。
key_len
表示查询使用了索引的字节数量。可以判断是否全部使用了组合索引。
Extra
Using where: 表示查询需要通过索引回表查询数据。
Using index: 表示查询需要通过索引,索引就可以满足所需数据。
Using filesort: 表示查询出来的结果需要额外排序,数据量小在内存,大的话在磁盘,有Using filesort 建议优化。
Using temprorary: 查询使用到了临时表,一般出现于去重、分组等操作。
回表查询
通过辅助索引无法直接定位行记录, 先通过辅助索引定位主键值,然后再通过聚簇索引定位行记录,它的性能比扫一遍索引树低。
覆盖索引
只需要在一棵索引树上就能获取SQL所需的所有列数据,无需回表,速度更快,这就叫做索引覆盖。将被查询的字段,建立到组合索引。
最左前缀原则
复合索引使用时遵循最左前缀原则,最左前缀顾名思义,就是最左优先,即查询中使用到最左边的列, 那么查询就会使用到索引,如果从索引的第二列开始查找,索引将失效。
LIKE查询和NULL查询
select * from user where name like ‘%o%’; //不起作用
select * from user where name like ‘o%’; //起作用
select * from user where name like ‘%o’; //不起作用
可以在含有NULL的列上使用索引,但NULL和其他数据还是有区别的,NULL列需要增加额外空间来记录其值是否为NULL。
索引与排序
MySQL查询支持filesort和index两种方式的排序,filesort是先把结果查出,然后在缓存或磁盘进行排序操作,效率较低。使用index是指利用索引自动实现排序,不需另做排序操作,效率会比较高。
filesort有两种排序算法:双路排序和单路排序。
index方式的排序
ORDER BY 子句索引列组合满足索引最左前列
WHERE子句+ORDER BY子句索引列组合满足索引最左前列
filesort方式的排序
对索引列同时使用了ASC和DESC
WHERE子句和ORDER BY子句满足最左前缀,但where子句使用了范围查询(例如>、<、in等)
ORDER BY或者WHERE+ORDER BY索引列没有满足索引最左前列
使用了不同的索引,MySQL每次只采用一个索引,ORDER BY涉及了两个索引
WHERE子句与ORDER BY子句,使用了不同的索引
WHERE子句或者ORDER BY子句中索引列使用了表达式,包括函数表达式
慢查询定位
开启慢查询日志: SHOW VARIABLES LIKE ‘slow_query_log%’
通过文本编辑器打开slow.log日志
time:日志记录的时间
User@Host:执行的用户及主机
Query_time:执行的时间
Lock_time:锁表时间
Rows_sent:发送给请求方的记录数,结果数量
Rows_examined:语句扫描的记录条数
SET timestamp:语句执行的时间点
select….:执行的具体的SQL语句
也可以通过分析工具查看,比如mysqldumpslow。
慢查询优化
如何判断是否为慢查询?
依据SQL语句的执行时间,它把当前语句的执行时间跟 long_query_time 参数做比较,超出记录日志,long_query_time 参数的默认值是 10s,该参数值可以根据自己的业务需要进行调整。
如何判断是否应用了索引?
根据SQL语句执行过程中有没有用到表的索引,可通过 explain 命令分析查看
查询是否使用索引,只是表示一个SQL语句的执行过程;而是否为慢查询,是由它执行的时间决定,不止要创建索引,还要考虑索引过滤性,过滤性好,执行速度才会快。
慢查询原因总结
1) 全表扫描:explain分析type属性all
2) 全索引扫描:explain分析type属性index
3) 索引过滤性不好:靠索引字段选型、数据量和状态、表设计
4) 频繁的回表查询开销:尽量少用select *,使用覆盖索引
分页查询优化
一般的分页查询使用简单的 limit 子句就可以实现
SELECT * FROM 表名 LIMIT [offset,] rows
如果查询偏移量变化,比如查询万,百万级后面的数据,就不能用简单的直接分页了
1) 利用覆盖索引优化
2) 利用子查询优化
select * from user where id>= (select id from user limit 10000,1) limit 100;
使用了id做主键比较(id>=),并且子查询使用了覆盖索引进行优化。
 微信打赏
微信打赏